Comunicación presentada al V Congreso Ciudades Inteligentes
Autores
- Elena Krasheninnikova, Senior Data Scientist, Ikusi
- Sergio Montero, Arquitecto Big Data, Ikusi
- Pedro Sánchez, Senior Product Manager, Ikusi
Resumen
Ikusi ha desarrollado un modelo predictivo que pronostica el nivel de ocupación de las bicicletas en cada estación del sistema para compartir bicicletas de San Sebastián. Se han tenido en cuenta los datos históricos sobre el alquiler de bicicletas en 16 estaciones durante más de dos años, junto con otros datos como el clima, eventos (por ejemplo, ferias, eventos deportivos, etc.) y días festivos en la ciudad y en regiones cercanas. Este trabajo demuestra que es posible predecir el nivel de ocupación para proporcionar conocimiento a ciudadanos, proveedores de servicios y el departamento de movilidad de la ciudad.
Palabras clave
Data Science, Big Data, Plataforma, Modelo Predictivo, Machine Learning, Smart Cities, Servicios Urbanos
Introducción: dotando de inteligencia a las ciudades del futuro
Las ciudades son un lugar perfecto para llenarlo de sensores de todo tipo: de presencia de peatones, calidad del aire, tráfico, sensores de prácticamente cualquier cosa. Todos ellos reportan una gran cantidad de datos que, sin tratarlos mediante técnicas de business intelligence, big data, data science, etc., no son más que ruido. También es cierto que debemos velar por la calidad del espacio urbano, y no contaminarlo con tecnología colgando de postes si no es necesario. Las ciudades ya cuentan con muchos sistemas de información, pero no está siendo analizada, cruzada, y tratada.
Además, hasta ahora la captación de la información se ha gestionado individualmente, desde la unidad administrativa en la que recae una competencia concreta de la ciudad. Un modelo de funcionamiento en vertical que ha generado un nutrido y heterogéneo ecosistema, compuesto por diferentes sistemas de información y aplicativos, que tiene deficiencias en su integración e, incluso, coordinación.
La incorporación de soluciones tecnológicas a la gestión de las ciudades está generando, por tanto, grandes cantidades de datos de forma permanente que es necesario transformar para obtener información de valor que permita afrontar los retos a los que se enfrentan las ciudades del siglo XXI.
No podemos olvidar que las ciudades son sistemas complejos, cada vez más complejos, en los que un cambio en una de sus variables altera el conjunto del sistema. Pensemos en realidades que están de plena actualidad como por ejemplo el notable incremento de turistas en muchas de nuestras ciudades. Desde un punto de vista estrictamente económico, los turistas generan ingresos y riqueza. Pero, si el análisis se realiza desde el punto de vista de la movilidad de los ciudadanos, el turismo masivo genera problemas de sostenibilidad en el transporte y, en los casos más extremos, de convivencia entre autóctonos y visitantes. La pregunta es: ¿cómo pueden las ciudades alcanzar el equilibrio entre sus diferentes retos?
Para que las soluciones tecnológicas adquieran un verdadero valor en la gestión de las ciudades, es necesaria una visión integrada y coherente, que aborde la ciudad como un todo y que sea capaz de cuadrar una ecuación con múltiples incógnitas, derivadas de su complejidad creciente.
Para ello es imprescindible superar la compartimentación de información que generan los diferentes departamentos, organismos e instituciones que intervienen en la gestión efectiva de la ciudad, de tal forma que se acometan estrategias y servicios desde una visión integral, conjunta y coordinada.
Ese es precisamente el objetivo de las Plataformas de Gestión Urbana que impulsan la integración, la interoperabilidad y la coordinación de las diferentes fuentes de información y aplicativos. Estas plataformas integrales, por y para la gestión de los servicios urbanos, centralizan, procesan y explotan datos en tiempo real, transformándolos en información útil con herramientas de business intelligence y big data para conocer el estado global de la ciudad en su conjunto. Asimismo, permiten realizar un seguimiento detallado de los diferentes procesos que dan soporte a las iniciativas encaminadas a la consecución de una ciudad más sostenible e inteligente.
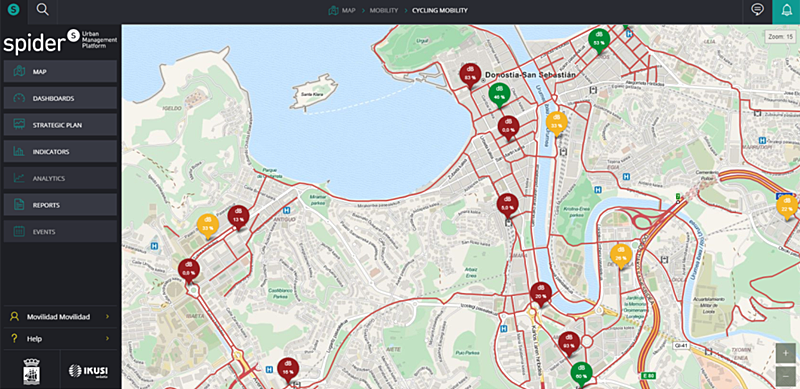
Un caso práctico: el sistema público de bicis eléctricas de San Sebastián
En la capital guipuzcoana uno de los medios de transporte público sostenible y de gran uso es la bicicleta eléctrica.
San Sebastián cuenta con dBizi, el primer sistema público de bicicleta 100% eléctrico. Su objetivo es impulsar la movilidad activa y sostenible en la ciudad de Donostia-San Sebastián ofreciendo una alternativa de transporte urbano saludable. El sistema está formado por 16 estaciones repartidas por la ciudad y 125 bicicletas eléctricas.
A día de hoy, a través del portal de dBizi el ciudadano puede saber el número de bicicletas disponibles en cada una de las 16 estaciones en tiempo real. Sin embargo, no es posible conocer la disponibilidad de bicicletas para una hora y un día determinado, extremo que ayudaría a fomentar la utilización de este tipo de servicios.
Ikusi ha desarrollado un modelo predictivo en torno al nivel de ocupación de las bicilcetas en las diferentes estaciones con el que los ciudadanos podrían planificar con antelación la ruta hasta la universidad, una reunión de trabajo o una comida con los amigos sabiendo que llegarán a tiempo porque tendrán la bicicleta disponible y, además, podrían saber con antelación que es posible devolver la bicicleta en la estación que deseen.
Por otro lado, desde el punto de vista del proveedor del servicio, la información sobre la distribución de bicicletas le ayudaría a planificar su correcta distribución y al ayuntamiento a prestar un servicio de mayor calidad. Con lo cual con un solo proyecto se podrían satisfacer las necesidades de los tres actores involucrados en este sistema de movilidad.
El primer paso para el desarrollo del modelo predictivo fue analizar en profundidad los datos históricos de los últimos cinco años. El conjunto de datos inicial contenía información de alquileres de cada estación con variables como fecha y hora del alquiler, estación de desenganche y enganche, duración del alquiler; en total 9 variables de bicicleta, usuario y estación.
Después se nutrieron los datos con fuentes adicionales como datos meteorológicos, calendarios de festivos y eventos en la ciudad y los alrededores y geolocalización de las estaciones.
Es muy importante tener en cuenta el contexto cuando se quiere predecir el comportamiento humano, como en este caso el uso de las bicicletas. ¿Cuál es el motivo para coger o no una bicicleta? Si llueve o hace sol, si es festivo en España o Francia, si es martes o domingo, si hay un partido de fútbol o un concierto de rock. Se han incorporado todos estos parámetros en el modelo predictivo que Ikusi ha diseñado.
Un paso adicional para que el modelo opere adecuadamente es limpiar bien el dataset, eliminando los registros anómalos que son ruidosos. A continuación, se crean variables adicionales transformando o combinando las que ya se disponían. En concreto, en la parte de analítica descriptiva se contaba con más de 60 variables.
El objetivo de la analítica descriptiva es entender el funcionamiento del sistema, contrastar algunas hipótesis intuitivas y detectar patrones. En muchas ocasiones sólo hace falta la parte de analítica descriptiva con buenas visualizaciones para contestar a algunas preguntas claves de negocio. Además, esta etapa ayuda a seleccionar los factores que realmente afectan a la variable objetivo.
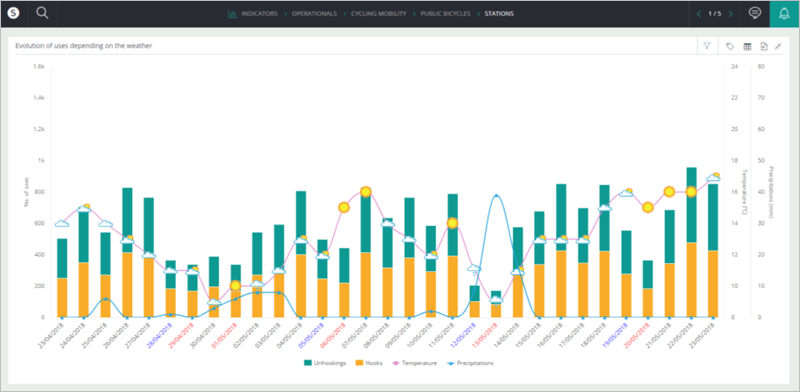
En el proyecto llevado a cabo por Ikusi se quería dar respuesta a preguntas como:
- ¿Cómo afectan los días festivos y eventos en España/Francia al funcionamiento del sistema?
- ¿Cuántos alquileres “fallidos” hay? ¿Por qué ocurren?
- ¿Cuál es el número de usuarios al día que usan bici pública?
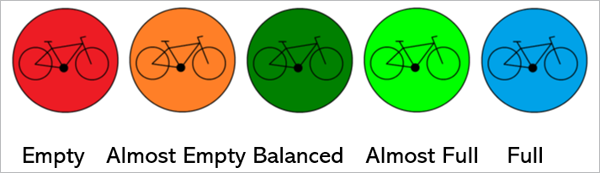
La siguiente etapa es el modelado de la parte de analítica predictiva. En este caso la variable objetivo es el nivel de disponibilidad de bicicletas en cada estación por hora. Esta variable tiene 5 niveles:
- L1 = 1 empty
- L2 = 2 almost empty
- L3 = 3 balanced
- L4 = 4 almost full
- L5 = 5 full
En Machine Learning, entre otros factores, el tipo de modelo define la variable objetivo. Con lo cual, en el presente caso, por ser una variable categórica de 5 niveles, estamos ante un caso de clasificación multiclase.
Como en cualquier framework de machine learning se procede a la selección de variables predictoras (que son el contexto), eliminando las no relevantes y correladas. Después se divide el dataset en dos: 80% de datos para el conjunto de entrenamiento y 20% para el test. El conjunto de test ayuda tanto a identificar el funcionamiento de un modelo en concreto, como a comparar diferentes modelos entre ellos.
En este proyecto se han entrenado una pila de modelos para clasificación multiclase:
- Regresión Logística Multiclase
- SVM
- Redes Neuronales Artificiales (ANNs)
- Balanceadas
- No balanceadas
- Random Forest
- Caret
- No caret
Calculando las métricas de los distintos modelos:
- Matriz de confusión
- Estadísticas generales
- Estadísticas por clase
Después del entrenamiento se comparó el rendimiento entre todos y, a través de una única métrica en común, se eligió la mejor. La métrica utilizada fue área bajo la curva ROC, que es una métrica robusta y frecuente en ciencia de datos. Tras escoger RANDOM FOREST con Caret la precisión del modelo se puede mejorar, así que se realizan diferentes pruebas para obtener mejor resultado:
- Reducir el tamaño de la muestra (solo 2017)
- Upsample
- SMOTE
- Variación de pesos para calcular la variable objetivo
Para validar el resultado final del modelo seleccionado se utilizaron los datos fuera de los conjuntos de entrenamiento y test, los datos nuevos. El área bajo la curva ROC ha sido de 74,4%, lo que para un problema de comportamiento de personas con un contexto cambiante representa un buen resultado, identificando bien las clases más críticas como Empty y Full.
Conclusiones
Ikusi ha desarrollado un modelo predictivo que pronostica el nivel de ocupación de las bicicletas en cada estación del sistema para compartir bicicletas de San Sebastián. Se han tenido en cuenta los datos históricos sobre el alquiler de bicicletas durante más de dos años en dieciséis estaciones, junto con otras características como el clima, eventos (por ejemplo, ferias, eventos deportivos, etc.) y días festivos en la ciudad y en las regiones cercanas.
Asimismo, se ha realizado un estudio de los tipos de uso del sistema de alquiler de bicicleta pública, ya que se detectó que había alquileres en los que no se podía acceder a una bici (alquiler espera), alquileres en los que se sacaba una bici y se devolvía al poco tiempo (alquiler nulo) y alquileres normales.
También se ha analizado el número de usuarios del sistema de alquiler en función de diferentes parámetros como estación, usuarios/día, usuarios/mes, por día de la semana, climatología, etc.
Por último, se ha desarrollado la interfaz gráfica con el mapa de la ciudad en la que se indica el nivel de ocupación en cada estación.
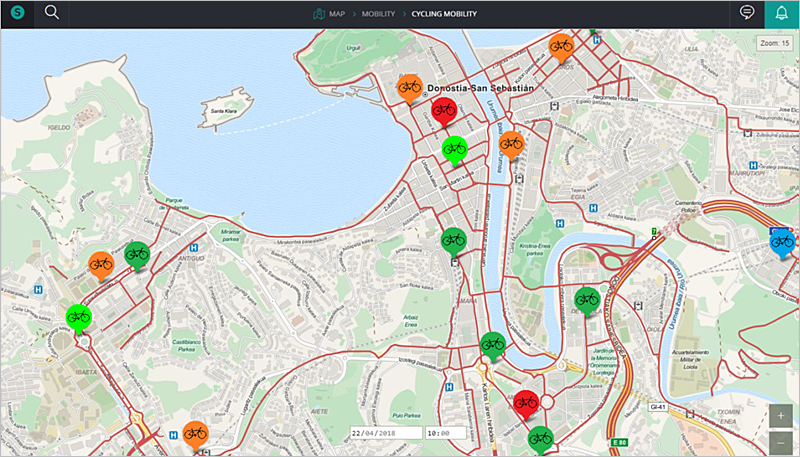
Con base en los datos disponibles, el trabajo demuestra que es posible predecir el nivel de ocupación para proporcionar conocimiento a los diferentes actores involucrados en la ciudad, es decir, ciudadanos, proveedores de servicios y departamentos de movilidad de la ciudad e impulsar este tipo de transporte para mejorar la movilidad urbana, al tiempo que se ayuda a reducir la emisión de gases contaminantes.