Comunicación presentada al VI Congreso Ciudades Inteligentes
Autor
Roberto García Lafuente, CEO, Dinycon Sistemas
Resumen
La movilidad peatonal en la ciudad es uno de los aspectos que mayor interés genera en los Ayuntamientos, ya que esta información le va a permitir hacer una mejor gestión de sus espacios públicos, al tener datos en tiempo real y una predicción de los mismos. Para ello partimos de una base de datos de afluencia peatonal a la Parte Vieja de San Sebastián por sus diferentes calles, generada a lo largo de estos últimos 5 años, dentro del proyecto Smartkalea, liderado por Fomento de San Sebastián. El objetivo es construir un modelo de datos predictivo en base a los históricos y a otros elementos del entorno (meteorología, eventos, etc.), tanto a corto plazo (horizonte de 1 hora aproximadamente) como a largo plazo en cualquier fecha del año, utilizando algoritmos para identificar patrones y tendencias que nos permitan predecir la movilidad peatonal en el horizonte de interés.
Como caso de uso, mostramos la aplicación de esta solución al control de aforo de las playas, donde además de la casuística de la meteorología, eventos y festivos, nos encontramos con otros factores como son las mareas y el estado de la mar, que van a hacer que el aforo varíe según estas circunstancias; el objetivo es poder ofrecer al bañista una información predictiva de la situación para que selecciones su playa dentro del abanico de opciones que tenga a su disposición.
Palabras clave
Control Aforo Playas, Modelos Predictivos, Calidad Dato, Aprendizaje Automático
Introducción
En la actualidad existe un gran número de sensores en el entorno de una ciudad que captan un volumen alto de datos; esta información se muestra normalmente en tiempo real y se establece la correlación entre diferentes fuentes de datos. La información es útil ya que nos da una ‘fotografía’ en tiempo real de lo que está ocurriendo en ese momento en la ciudad; del registro de estos datos obtenemos unas estadísticas que nos van a permitir tener un registro fiel de lo que acontece e incluso medir el impacto de unas variables del entorno sobre otras.
Sin embargo, consideramos de alto interés el poder obtener datos predictivos, partiendo de un registro histórico de los mismos, que nos permitirán tomar decisiones en el corto plazo, adelantándonos a situaciones que previsiblemente van a ocurrir y tomar las decisiones adecuadas. En nuestro caso, trasladamos estos conceptos a la movilidad peatonal que es uno de los aspectos más relevantes en la dinámica de una ciudad.
Para ello vamos a trabajar con datos históricos registrados dentro del proyecto Smartkalea, liderado por Fomento de San Sebastián, con el objetivo de mejorar el funcionamiento de la Parte Vieja de San Sebastián, tanto en aspectos como es el ahorro energético, la gestión de residuos y la movilidad peatonal, siendo este último el que vamos a abordar en esta Comunicación.
Análisis preliminar y alcance
Se proporcionan datos obtenidos cada 15 minutos de 7 sensores en las siguientes localizaciones de la Parte Vieja de San Sebastián. Los sensores están ubicados en las principales entradas a la Parte Vieja donostiarra, por donde fluye aproximadamente el 90% del tráfico peatonal; hay otros puntos de entrada no sensorizados, que corresponderían al flujo restante. El flujo de personas en el interior del área está por tanto definido parcialmente, pudiendo haber personas que entran y salen por puntos sensorizados, que entran por puntos sensorizados y salen por puntos no sensorizados (o viceversa), o que entran y salen por puntos sin sensorizar; el porcentaje de las calles sensorizadas nos da información relevante de la dinámica peatonal de esta zona de la ciudad
Construcción del dataset para los modelos conceptuales
Del análisis de los datos en bruto, hubo que realizar un análisis y depuración de los mismos utilizando herramientas estadísticas, de modo que se eliminaron valores desproporcionados y se completaron algunos intervalos en los que faltaban datos con simples interpolaciones lineales, de modo que finalmente obtenemos un conjunto de datos coherentes sobre los que se va a trabajar. En total se dispone de 540.000 instancias de datos
Dentro del histórico disponible se va a seleccionar un periodo en el que se disponga de datos de todos los sensores, de forma que se obtengan unas conclusiones más completas, teniendo en cuenta que el dicho periodo sea significativo; seleccionamos el intervalo entre el 12 de agosto de 2017 a las 0:00 hasta el 18 de abril de 2018 a las 23:59. Con este dataset de 250 días se ha separado un conjunto de días que serán usados como días de test, correspondientes al último 25% del dataset, 62 días de febrero, marzo y abril del 2018. El 75% anterior se utilizará como conjunto de entrenamiento y validación de los modelos aplicados posteriormente.
Predicción a corto plazo
Los datos disponibles una vez interpolados permiten hacer predicciones a corto plazo (unos pocos steps o periodos de 15 minutos en el futuro). Para ello se construye un modelo predictivo que tiene que como entradas una ventana de lecturas anteriores al dato a predecir, y como salida el dato predicho. Posteriormente se comparan los resultados con los valores reales para estimar la eficacia del modelo. Este método es similar a una predicción ARIMA (modelos auto regresivos), con la diferencia de que al modelarse como un dataset de train y otro de test, permite incorporar al modelo otros factores, pudiendo mejorar su capacidad predictiva.
Método
El método se define por 2 parámetros fundamentales, la profundidad o tamaño de la ventana y el horizonte de predicción. El tamaño de la ventana m define cuántas observaciones anteriores se tienen en cuenta para predecir cada valor, y el horizonte h, cuántos steps en el futuro se predicen. A partir de estos dos parámetros, y partiendo del esquema presentado en la Figura 1 se va construyendo un dataset cuyas instancias tienen m features, y cuya variable de salida está definida por la observación m+h.
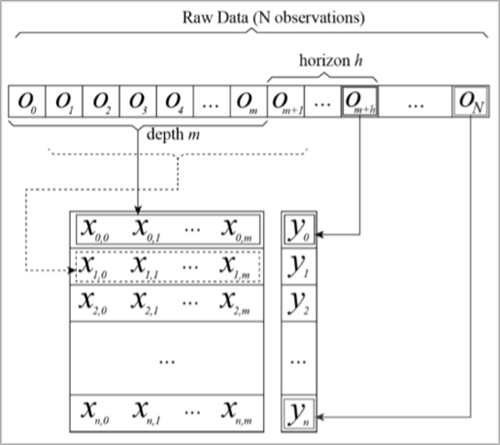
Sobre este dataset obtenido de todos los datos disponibles de 9 meses (24.000 datos, 250 días x 96 lecturas diarias), se separa alrededor de un 25% que no se usarán para entrenar. Como se indicaba anteriormente, esto corresponde a unos 62 días de febrero, marzo y abril de 2018, que supondrán el conjunto de test, o los datos que vamos a intentar predecir. Con el otro 75% se entrena un modelo predictivo diseñado para estos datos al que, cuando se le introducen las features X del conjunto de test, nos devolverá predicciones Ypred que al contrastarse con las Ytrue nos proporcionará el rendimiento del modelo. En el caso del prototipo planteado, se obtienen todas las predicciones para las lecturas de los 62 días de una sola vez, al evaluar el modelo con los datos de test. En un entorno de predicción, se habría entrenado el modelo para todos los datos, en vez de sólo con un 75%, y se podrían ir obteniendo predicciones de una en una cada 15 minutos.
Resultados
Los modelos predictivos se han elaborado para las series temporales de entrada y salida de cada uno de los sensores, para los horizontes de predicción 1, 2 y 3 (15, 30 y 45 minutos) con ventanas de 20 posiciones. Por ejemplo, para predecir el número de personas que pasarán por un sensor, si son las 16:00 y se quiere predecir el de las 16:15 (1 step), se creará una instancia con los valores ya observados entre las 11:00 y las 16:00 (5 horas, 20 valores), y se introducirá en el modelo entrenado, obteniendo un valor para las 16:15.
Los resultados en detalle pueden observarse en la web (Figura 2), donde se observa que dependiendo del sensor, las salidas o las entradas, la predicción es más o menos ajustada a los datos reales, con coeficientes de correlación R2 superiores a 0.7, y errores cuadráticos medios entorno a las 30 personas. Lo que significa que la predicción en estos sensores es acertada con un error aproximado de 30 personas. Obviamente, aumentando el horizonte de predicción, ésta se degrada, invariablemente para todas las localizaciones.
Estos modelos predictivos básicos pueden mejorarse de muchas maneras aumentando la calidad de esta predicción. La forma más directa es incluir en las features, que actualmente sólo son lecturas anteriores a la lectura a predecir, variables que conozcamos que son influyentes para los perfiles de flujo de personas, como podrían ser variables meteorológicas, variables de eventos (culturales, deportivos, etc.), o variables de calendario. Por ejemplo, si las instancias con las que entrenamos el modelo, además de contener información de lecturas anteriores, tienen información del día de la semana en que se están produciendo, el modelo estará mejor preparado para hacer predicciones considerando también esta información.
Estos modelos, aun tratándose de modelos a corto plazo que no permiten observar un comportamiento macroscópico del comportamiento de los flujos de peatones, tras un buen entrenamiento con todos los factores que sean necesarios, sí permiten analizar y predecir qué va a pasar en los siguientes minutos u horas a una situación dada (por ejemplo cuánta gente va a entrar por un determinado sensor cuando finalice la celebración de un evento), permitiendo tomar acciones correctoras en caso necesario.
Predicción a largo plazo
De manera análoga a la sección anterior, se establece un método para obtener estimaciones a largo plazo del flujo de peatones por los sensores. Estas estimaciones estarán basadas en caracterizaciones temporales de los sensores. Aunque las estimaciones a largo plazo son menos precisas con la técnica presentada, se pueden obtener para cualquier momento futuro, y sin depender de disponer de lecturas inmediatamente anteriores, como ocurre con la predicción a corto plazo. Además, puede construirse el modelo de forma que vaya actualizándose y corrigiéndose a medida que se tengan nuevas observaciones.
Método
El método de predicción a largo plazo se basa en la detección de patrones en los datos conocidos. Los datos se agrupan por días, y éstos se agrupan por similitud, formando patrones. De esta manera, pueden agruparse por ejemplo, todos los sábados, que tienen un perfil de flujos similares. Si se conoce cuál es el perfil típico de un sábado (por ejemplo, la media de los otros sábados), bastará con usar ese perfil como predicción para cualquier sábado venidero, y por lo general, y salvo que concurran circunstancias especiales, la predicción dada por el perfil será suficiente.
Cualquier día del futuro puede transformarse a este tipo de features, ya que son conocidas para cualquier día. De esta manera, se puede construir una instancia, y clasificarla en función del modelo de clasificación entrenado antes, y obtener una clase. La predicción de flujo para ese día será el centroide de los días que pertenecen al clúster indicado por esa clase.
Además, y aunque no se haya aplicado al caso de uso, se dispone de una serie de algoritmos diseñados para encontrar cambios de tendencias y realizar microadaptaciones a las predicciones a largo plazo de forma que en el día a día puedan ser útiles también.
Resultados
La prueba de este modelo se ha realizado usando la misma partición que para la predicción de corto plazo. En principio cualquier día del año puede ser predicho, pero sólo podemos evaluar la calidad de la predicción si tenemos un dato de flujo real, por tanto se ha separado un 25% de días para testear el modelo entrenado con los otros 75
Aunque aparentemente los valores de rendimiento son bajos, hay que tener en cuenta todos estos factores para considerar que este método puede mejorarse considerablemente con un análisis en profundidad de los comportamientos estacionales en cada sensor, y añadir otras features al clasificador como eventos que se repiten o factores meteorológicos. Por otra parte, existen mecanismos que no se han aplicado en este sistema, para corregir online errores de clasificación, de forma que la predicción pueda adaptarse.
Ha de destacarse que este método no ofrece sólo predicciones, sino una herramienta para analizar los modelos de días típicos que pueden producirse en una localización, y cómo se diferencian entre sí.
Predicción contextual y correlación entre sensores
La predicción contextual es una técnica que permite obtener predicciones (implementada a corto plazo, aunque podría extenderse al largo plazo) de los resultados que va a obtener un sensor, usando como entradas los datos capturados por los demás sensores. Esto tiene diferentes e interesantes aplicaciones como:
- Predicción en un lugar en el que no hay sensor, previo modelado con un sensor temporal durante un periodo de tiempo. Por ejemplo, podrían ubicarse sensores de forma temporal (sólo algunos meses) en el resto de entradas a la Parte Vieja donostiarra, para entrenar modelos. Posteriormente estos modelos permitirían estimar el número de personas que circulan por estos puntos, sin contar con un sensor.
- Establecer correlaciones entre sensores, pudiendo analizar cómo se comportan en función de los demás (si hay correlación), o descartar esta relación (si no hay correlación) y con otros puntos de la ciudad.
Método
El método de predicción funciona de forma análoga al método presentado para la predicción a corto plazo, con la diferencia de que en este caso en vez de usar una ventana de observaciones del sensor predicho, se usan tantas ventanas de observaciones como sensores circundantes haya, y todas las features que suponen las observaciones anteriores de cada uno de los otros sensores componen las variables de entrada de la instancia, cuya variable de salida es el dato a predecir, la observación en el sensor objetivo.
Posteriormente, se entrena el modelo con un porcentaje de datos para entrenamiento y se evalúa con otro porcentaje. En el caso de uso actual se han usado los mismos porcentajes que en los otros dos modelos. La ventana fijada para cada sensor es de 1 observación, de forma que cada instancia sólo tiene 6 features, y una variable de salida. Es decir, la predicción de las 16:15 se obtiene a partir de los valores de flujo a las 16:00 de todos los demás sensores.
Resultados
De los resultados de la tabla se desprende que salvo en la ubicación 5, para la que hay abundantes lecturas con valor 0, y esto no puede ser predicho, para el resto de localizaciones, es posible obtener predicciones de las salidas a partir de las entradas de los demás sensores. Es importante resaltar que debido a la ubicación de los sensores y la presencia de otras posibles salidas y entradas sin sensorizar, las salidas registradas en un sensor están contribuidas por personas que han entrado por las otras localizaciones, pero también por personas que han entrado por otros sitios sin ser detectadas. A pesar de ello, los errores se mantienen entorno a las 30 personas, siendo unas predicciones razonablemente buenas.
Caso de uso: control de aforo en playas
El modelo descrito en esta comunicación tiene varios campos de aplicación; uno de los más relevantes en el momento actual, derivado de la crisis sanitaria provocada por el COVID-19, es el control de aforo en playas, al ser estos espacios muy demandados en la época estival y más teniendo en cuenta el peso importante en el PIB del sector turístico.
Implantar un modelo de este tipo permitirá hacer un uso más racional y seguro de las playas, ya que el bañista podrá planificar el momento más adecuado de acudir a la playa, en base a la situación real y predicción de este modelo. Para una gestión más eficaz y segura de las playas, tenemos que tener en cuenta los siguientes aspectos:
- Aforo dinámico
- Registro de datos de afluencia y ocupación
- Información al público
- Seguridad
Aforo dinámico
Uno de los factores que más influye en el aforo de las playas son las mareas, especialmente en las zonas donde la diferencia entre pleamar y bajamar es elevada; también el estado de la mar y el oleaje
Para gestionar de forma adecuada la ocupación en playas, tenemos que introducir el concepto de aforo dinámico, estimando el espacio disponible en función de esta superficie. Este aforo se puede estimar por dos vías diferentes:
- Estimación del aforo de la playa en base a los datos recogidos de la tabla de las mareas y a la predicción meteorológica del estado de la mar: disponiendo del registro de mareas, teniendo en cuenta la morfología de la playa y el estado de la mar, se puede tener una aproximación de la superficie disponible en cada momento.
- Estimación del aforo en tiempo real mediante análisis de imágenes: con el despliegue de un conjunto de cámaras con visión sobre todo el arenal, de forma que se detecte la lámina de agua y su límite con la arena y a partir de ahí calcular en tiempo real la superficie de arenal disponible; esta opción, que en teoría sería la más ajustada a la realidad, tiene una cierta complejidad para su implantación.
Adicionalmente, en el cálculo del aforo, se pueden tener en cuenta factores adicionales, que están presentes en la dinámica de funcionamiento de las playas:
- Número de personas paseando por la orilla: es un fenómeno bien conocido y se puede estimar un porcentaje de usuarios de la playa que realizan esta actividad; de aquí podemos determinar un factor de corrección para aplicar al aforo
- Número de personas que se están bañando: normalmente hay un porcentaje continuo de bañistas; podemos también establecer un factor de corrección del aforo en base a esa estimación
- Superficie del arenal dedicada a actividades deportivas o a los toldos: sería un dato directo para reducir la superficie disponible del arenal y con ello calcular el aforo
Teniendo en cuenta todo lo anterior y una vez establecido por la autoridad competente el espacio que requiere cada persona, conociendo la superficie disponible, obtenemos automáticamente el dato del aforo.
Registro de datos de afluencia y ocupación
Es necesario sensorizar el arenal para tener el dato de ocupación: se pueden desplegar 2 tipos de tecnologías o una combinación de ambas:
- Cálculo de la ocupación mediante analítica de imágenes: se instala un conjunto de cámaras distribuidas a lo largo del arenal y con un proceso de analítica de imágenes, extraemos el número de personas en el mismo.
- Conteo en los accesos al arenal mediante sensores: será viable siempre que los accesos al arenal estén delimitados; es más precisa y nos aportaría datos estadísticos de afluencia por los accesos y franjas horarias, que se pueden utilizar con fines estadísticos y como base para la construcción del modelo predictivo.
Información al público
Es fundamental que el público disponga de información veraz y en tiempo real; se indican algunos canales:
- Monitor de aforo en accesos a las playas: indica el nivel de ocupación en tiempo real; se instala en los accesos
- Información a través de la web municipal: el usuario puede acceder a los mismos para su toma de decisiones
- APP informativa: descargando una APP que ofrece la información de ocupación de los arenales y en base a ello, decidir a qué arenal dirigirse.
Con el registro de datos históricos, se construirá un modelo predictivo de ocupación para las próximas horas, información que puede ser de mayor interés para el usuario que está planeando ir a la playa pero que tardará un tiempo en llegar a las mismas.
Seguridad
Para garantizar la seguridad, se configuran alarmas de aforo (por ejemplo, cuando haya un 95% de la ocupación o se alcance el aforo), que automáticamente se envían a las personas responsables de seguridad para tomar las medidas adecuadas y limiten los accesos.
Teniendo en cuenta que el aforo es dinámico, nos encontraremos en una situación compleja de gestionar, cuando sube la marea, ya que el aforo se va reduciendo y con ello parte de los usuarios deberían salir del arenal. Se podría dar algunas pautas a los usuarios, apelando a la responsabilidad individual, del tiempo de estancia en la playa (por ejemplo, 3 horas) y avisar por megafonía en la franja horaria que sube la marea, si previsiblemente la ocupación de la playa y la reducción del aforo que se produce, pudieran poner en riesgo la ocupación.
Referencias
- Antonini, G., Bierlaire, M., & Weber, M. (2006). Discrete choice models of pedestrian walking behavior. Transportation Research Part B: Methodological, 667-687.
- Ashok, K., & Ben-Akiva, M. E. (1993). Dynamic origin-destination matrix estimation and prediction for real-time traffic management systems. International Symposium on the Theory of Traffic Flow and Transp. Berkeley.
- Laña, I., Olabarrieta, I., Vélez, M., & Del Ser, J. (2018). On the imputation of missing data for road traffic forecasting: New insights and novel techniques. Transportation research part C: emerging technologies, 18-33.
- Lee, J. Y., Lam, W. H., & Wong, S. (2001). Pedestrian simulation model for Hong Kong underground stations. Intelligent Transportation Systems, (págs. 554-558).
- Peterson, A. (2003). Origin-destination matrix estimation from traffic counts.
- Zhao, J., Rahbee, A., & Wilson, N. H. (2007). Estimating a Rail Passenger Trip OriginDestination Matrix Using Automatic Data Collection Systems. Computer-Aided Civil and Infrastructure Engineering, 376-387.