Comunicación presentada al V Congreso Ciudades Inteligentes
Autores
- Javier Carpintero Ordóñez, Cloud & IoT Presales Manager, NEC Iberica
- Javier Concha, Cloud & IoT Business Director, NEC Iberica
Resumen
En la actualidad, los proveedores de soluciones para ciudades inteligentes, industria o vehículos conectados, entre otros, se enfrentan a una complejidad y coste crecientes para administrar infraestructuras distribuidas geográficamente para soportar los distintos servicios IoT ofrecidos, especialmente aquellos que requieren una baja latencia. FogFlow es un framework de ejecución distribuido que dinámicamente orquesta los diferentes servicios IoT en la nube y los bordes (Edge) con el fin de reducir el consumo de ancho de banda y ser capaz de ofrecer una baja latencia, ofreciendo una calidad de servicio (QoS) optimizada. Partiendo del concepto de Edge-Computing, centrado en el procesamiento de los datos en una zona cercana al punto de generación por dispositivos con capacidad de análisis y proceso como routers o gateways, el Fog-Computing extiende este concepto y se refiere a la interconexión y comunicación entre el Edge y la nube.
Palabras clave
FogFlow, Fog-Computing, Edge-Computing, Cloud-Computing, IoT, FIWARE, NGSI
Introducción
El conocido como Internet de las Cosas (IoT) habilita una sociedad hiperconectada en la que cada vez más y más objetos como coches, drones o edificios se encuentran conectados y se convierten en elementos inteligentes, esto es, capaces de sentir y reaccionar a situaciones en tiempo real utilizando la información disponible de sensores y fuentes de datos.
Todos estos objetos inteligentes son gobernados normalmente por servicios que se ejecutan en infraestructuras de backend y que implementan complejas lógicas de procesamiento de datos. Uno de los grandes retos hoy en día es habilitar métodos fáciles, rápidos y eficientes de orquestar los servicios de backend y poder reaccionar con la máxima rapidez y utilizando el máximo de información posible.
A diferencia de las analíticas de datos tradicionales, la orquestación de servicios IoT debe tener en consideración los siguientes puntos singulares:
- Nuevos datos son generados constantemente por los sensores, y no es sostenible enviar todos los datos en bruto (“raw”) a servicios cloud centralizados para su procesado, debido fundamentalmente a las restricciones de ancho de banda y latencia. El procesamiento de datos debe descargarse dinámicamente sobre el “edge”, esto es, cerca de la fuente de datos.
- Los datos y el conocimiento existente deben poder compartirse e intercambiarse entre dispositivos, servicios, aplicaciones y plataformas.
- Las cargas de trabajo del sistema son dinámicas. Los dispositivos, servicios y aplicaciones se mueven, reconectan o desaparecen. Esto lleva a cargas y flujos de datos en constante cambio.
- Algunos servicios IoT requieren baja latencia y un tiempo de respuesta muy rápido.
- Las infraestructuras de backend necesitan administrar recursos y dispositivos muy heterogéneos y geográficamente distribuidos.
Todos estos aspectos suponen nuevos desafíos y añade un alto grado de complejidad tecnológica a los proveedores de infraestructura para administrar los diferentes servicios IoT ofrecidos. En este sentido, FogFlow está diseñado para encargarse de estos problemas complejos y ayudar a administrar estos servicios IoT de manera automática y eficiente en un entorno compartido y distribuido. FogFlow provee un modelo de programación estándar y centrado en el dato para que los proveedores de servicios puedan de manera sencilla y rápida adaptarse a las demandas.
Funcionamiento de FogFlow
En FogFlow, un servicio IoT es definido como un flujo de procesamiento de datos representado por operadores vinculados. Un operador toma información directamente de los dispositivos IoT o de partes anteriores del flujo de procesamiento, realiza una cierta lógica de negocio del servicio IoT y pasa el resultado al siguiente operador. Las tareas se vinculan entre sí durante el tiempo de ejecución en función de la dependencia de datos entre entradas y salidas.
Como se muestra en la figura, los servicios se organizan como flujos de procesamiento dinámicos entre productores (por ejemplo, sensores) y consumidores (como actuadores o aplicaciones) para realizar el procesado de datos necesario.
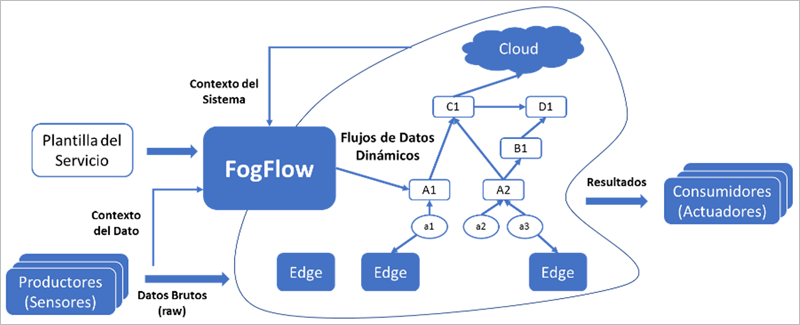
En primer lugar, los desarrolladores de servicios deben crear una plantilla del servicio para definir la lógica del mismo. FogFlow proporciona un editor de flujos gráfico basado en web para el diseño de las diferentes tareas. La plantilla del servicio representa la lógica abstracta y estática de procesamiento de datos del servicio IoT, incluidos los detalles sobre qué operador se utiliza para tomar qué entrada y producir qué salida, y también cuando y como debe activarse el operador. Los proveedores de servicios pueden así mismo reutilizar operadores ya registrados o implementar sus propios operadores.
Una vez definida la plantilla, el sistema monitorea la información de contexto de los datos disponibles en el sistema en tiempo de ejecución para determinar cuándo y cómo se debe instanciar el servicio. Así mismo, FogFlow también determina cuantas instancias de tarea se requieren para cada operador y también las configuraciones detalladas de cada instancia.
La estructura de datos de todos los flujos de datos se describe según un mismo modelo de datos normalizado denominado NGSI. FogFlow puede aprender qué tipo de datos se crean en cada nodo del borde (edge) y lanzar flujos dinámicos de procesamiento de datos para cada nodo en función de la disponibilidad de la metainformación de contexto registrada. Aplicando algoritmos de optimización se determina automáticamente, en qué lugar implementar las instancias de tarea de acuerdo con el contexto del sistema en tiempo real, como puede ser la cantidad de recursos disponibles en cada nodo edge o la carga de trabajo prevista.
Respecto a otros frameworks existentes, FogFlow presenta las siguientes características únicas:
- Programación centrada en los datos: Facilita el diseño y uso de los servicios IoT al proporcionar un modelo de programación centrado en los datos para diferentes roles o puntos de vista, de cara a expresar los objetivos en diferentes niveles de una manera más intuitiva. A nivel de operador, los proveedores solo tienen que anotar qué tipo de datos pueden manejar, qué funcionalidad se proporciona y qué tipo de resultados se producen. A nivel de servicio, los diseñadores pueden componer fácilmente diferentes operadores para configurar las plantillas del servicio en pocos minutos. Por último, los usuarios del servicio pueden definir a alto nivel el uso que va a tener el dato, de cara a que, durante el procesamiento de datos en tiempo de ejecución, FogFlow pueda organizar automáticamente los flujos en función de esta información.
Los usuarios del servicio pueden ser tanto productores de datos como consumidores de los resultados. Desde la perspectiva del productor, pueden establecer qué tipo de lógica se aplicará a sus datos, mientras que desde la perspectiva del consumidor pueden fijar el tipo de resultado que se generará. Lo que hace FogFlow es “traducir” estos objetivos de uso de los datos definidos a alto nivel en flujos de procesamiento concretos, para después desplegarlos y mantenerlos sin interrupciones en los nodos cloud y edge disponibles de la manera más eficiente posible. Más relevante aún resulta que, con este modelo de programación centrado en el dato y basado en un modelo de datos estándar, los flujos de procesamiento subyacentes pueden compartirse y optimizarse entre múltiples servicios y usuarios.
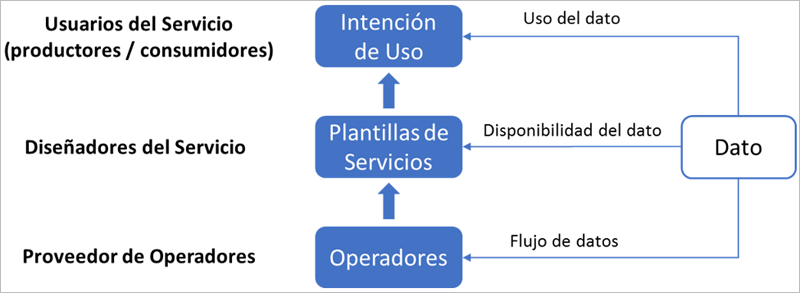
- Gestión Autónoma: FogFlow puede llevar a cabo decisiones de orquestación de servicios de IoT de manera descentralizada y autónoma. Esto significa que cada nodo edge puede tomar sus propias decisiones teniendo en cuenta solo una vista de contexto local. De esta manera, la mayoría de las cargas de trabajo se pueden manejar directamente en los bordes sin depender de una nube central. Este enfoque «sin nubes» permite no solo poder proporcionar un tiempo de respuesta rápido, sino que también permite obtener una gran escalabilidad y fiabilidad.
- Implementación optimizada: La configuración de las tareas y la implementación de los flujos de procesamiento se optimizan para que el entorno completo cloud-edge cumpla determinados objetivos, por ejemplo, minimizar el tráfico interno de datos entre los nodos cloud y edge o minimizar la latencia a la hora de producir los resultados. Cabe destacar que la optimización de flujos de procesamiento de datos no solo ocurre al inicio del servicio, sino que continúa durante toda la vida útil del servicio adaptándose el mismo de forma dinámica. Uno de estos comportamientos de optimización es la migración dinámica de tareas de un borde a otro para mantener el tiempo de respuesta mínimo para objetos móviles, como pueden ser smartphones, coches conectados o drones.
Modelos de Programación
En la actualidad FogFlow proporciona dos modelos de programación diferenciados para admitir diferentes tipos de patrones de carga de trabajo que pasamos a exponer a continuación.
Topología de Servicio
El primer patrón es activar los flujos de procesamiento necesarios para producir algunos datos de salida solo cuando los consumidores solicitan los datos de salida.
Para definir un servicio IoT basado en este patrón, el proveedor de servicios necesita definir una topología de servicio, que consiste en un conjunto de operadores vinculados en el que cada operador está definido con una granularidad específica. FogFlow tomará en cuenta la granularidad del operador para decidir cuántas instancias de tarea de dicho operador se deben instanciar en función de los datos disponibles.
Una topología de servicio debe ser activada explícitamente por una petición emitida por un consumidor o aplicación. La petición definirá qué parte de la lógica de procesamiento en la topología de servicio debe activarse y también puede definir opcionalmente un alcance geográfico específico, de cara a filtrar las fuentes de datos para aplicar la lógica de procesamiento activada.
Topología de Niebla
El segundo patrón está diseñado para un escenario en el que los diseñadores del servicio no conocen a priori la secuencia exacta de pasos de procesamiento de la secuencia. En su lugar, pueden definir una función de niebla o función fog para incluir un operador específico que manejará un tipo de información. FogFlow puede crear la gráfica de flujos de procesamiento en base a esta descripción de todas las funciones fog.
A diferencia de la topología de servicio, esta topología de niebla es una topología muy simple, con un solo operador que se activa cuando sus datos de entrada están disponibles. Dado que se pueden encadenar automáticamente diferentes funciones de niebla y permitir que más de una función de niebla maneje los nuevos datos, durante el tiempo de ejecución se pueden activar y administrar automáticamente nuevas instancias en función de la carga de datos.
Desde la perspectiva del diseño, la función de niebla es más flexible que la topología de servicio, ya que la lógica de procesamiento general de un servicio IoT se puede modificar fácilmente con el tiempo, agregando o eliminando funciones de niebla cuando la lógica de procesamiento del servicio deba modificarse para dar respuesta a nuevos requisitos. Con este modelo de programación basado en funciones de niebla, FogFlow soporta arquitecturas de computación sin servidor (serverless computing) en entornos cloud-edge.
Casos de Uso
A continuación, se explican dos casos de uso en los que FogFlow puede emplearse para el diseño de servicios de Smart. El primero de ellos está basado en la topología de servicio, mientras que el segundo está basado en funciones de niebla.
Buscador de Niños Perdidos
Este caso de uso pretende localizar a un niño perdido lo antes posible aprovechando la computación edge habilitada por FogFlow. Supongamos que hay una importante cantidad cámaras desplegadas en la ciudad a la que se tiene acceso. Como parte de la infraestructura de la ciudad, algunos nodos edge como gateways IoT de distintos servicios de la ciudad se implementan para ser administrados por FogFlow.
Un servicio fácilmente implementable basado en FogFlow para la localización del niño usando la topología de servicio podría ser la siguiente, contando el mismo de tres operadores diferentes:
- Extracción de rostros, encargado de reconocer y extraer imágenes de rostros de secuencias de video de las cámaras existentes.
- Generación de rasgos, que, en base a una imagen de rostro, calcula el vector de características únicas para cada rostro detectado.
- Coincidencia de rostros, que compara los rostros detectados con una imagen de referencia (la cara del niño perdido) en términos de sus vectores de características y rasgos.
Cabe destacar que se define una granularidad diferente para cada operador en la topología de servicio, por ejemplo, la coincidencia de rostros se instancia por cada persona a detectar, mientras que los otros dos operadores se instancian por cada cámara.
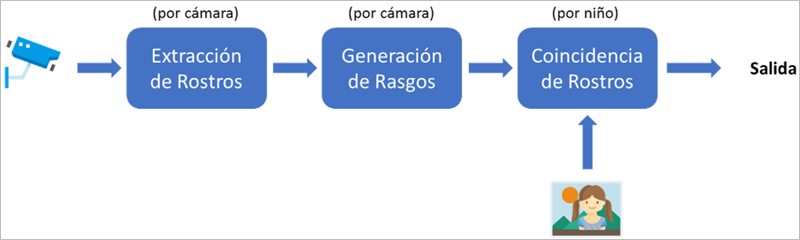
Para disparar esta topología de servicio, una aplicación externa debe realizar la petición y suscribirse a la salida del operador de coincidencia de rostros para obtener el resultado. Al cambiar el alcance geográfico definido para la petición, la aplicación externa puede controlar FogFlow para orquestar la topología de servicio con un alcance geográfico cambiante. En nuestro caso de uso, la búsqueda comenzaría en un ámbito pequeño y se expandiría el radio de búsqueda progresivamente paso a paso si el niño no es localizado.
En este ejemplo la aplicación externa, que actúa como consumidor, resulta muy simple, ya que es FogFlow quien maneja toda la complejidad de cómo organizar dinámicamente los flujos de procesamiento de datos para un alcance geográfico variable.
De acuerdo a experimentos realizados, se consigue reducir el ancho de banda consumido en hasta un 95% respecto a una aproximación tradicional basada plenamente en cloud.
Aparcamiento Inteligente
Se trata de un caso de uso real implementado en la ciudad de Murcia, desarrollado conjuntamente con la Universidad de Murcia. Se distinguen dos tipos de parking en la ciudad. Por un lado, zonas de estacionamiento regulado operadas por el Ayuntamiento y que pueden proporcionar información histórica sobre cómo se utilizan las plazas por día, y por otro lado parkings privados, operados por empresas privadas, y que pueden proveer información en tiempo real sobre la disponibilidad de plazas. Utilizando estos dos tipos de información y otra información pública disponible de transporte, el servicio de aparcamiento inteligente planteado puede proveer información en tiempo real y recomendaciones de aparcamiento personalizadas para cada conductor.
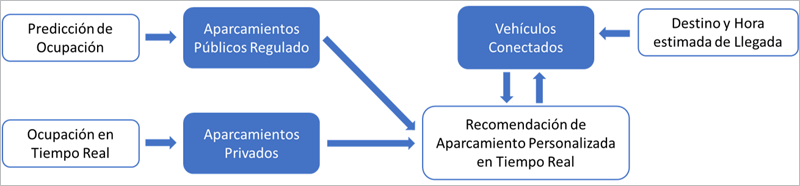
En este caso, no resulta fácil aplicar una topología de servicio, pero haciendo uso de funciones fog la lógica de procesamiento de datos resulta sencilla. Como se observa en la Figura, solo es necesario diseñar e implementar funciones fog dedicadas para cada objeto o variable involucrada en el caso de uso.
En este ejemplo se implementaría una función de niebla por cada zona de aparcamiento regulado públicas para realizar la predicción de cuantas plazas estarán disponibles en base a la información histórica de uso, así como otra para realizar las estimaciones de ocupación en los aparcamientos privados. Por su parte, los vehículos conectados por una parte aportan información sobre su ruta y hora estimada de llegada al destino, y por otra parte esperan recibir una recomendación personalizada sobre el mejor aparcamiento disponible a su llegada, por lo que por cada vehículo se contará con dos funciones de niebla.
Estas instancias se encuentran desplegadas en nodos edge cercanos al origen de cada uno de los datos de entrada, consiguiendo una reducción de ancho de banda cercana al 50% frente a enfoques tradicionales y consiguiendo proveer información actualizada en tiempo real y personalizada para cada vehículo.
Integración con FIWARE
El módulo FogFlow ha sido promovido como Generic Enabler (GE) en la comunidad de código abierto FIWARE. Dentro de esta comunidad, ocupa una posición única como orquestador Cloud-Edge de cara a manejar flujos de datos dinámicos sobre la nube y los bordes de la red para la ingesta de datos, transformación o conseguir análisis avanzado. Como Generic Enabler FIWARE puede trabajar coordinadamente con otros módulos de FIWARE de manera nativa y proveer servicios avanzados a distintas plataformas inteligentes.
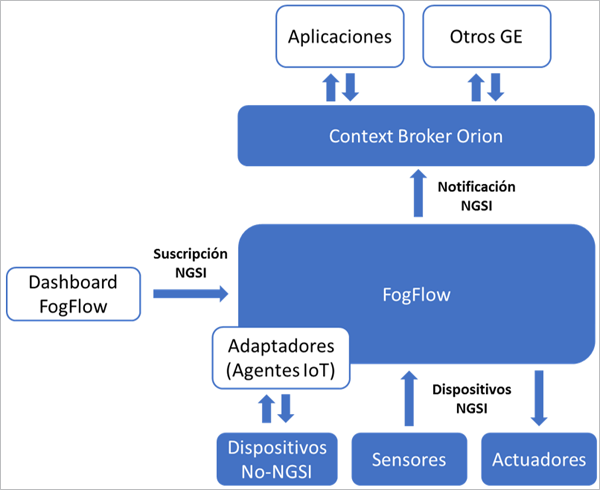
Por un lado, FogFlow puede trabajar conjuntamente con el Context Broker Orion, pieza central de FIWARE y la mayoría de plataformas inteligentes basadas en esta iniciativa, mediante interfaces NGSI estandarizadas, y a través de esta con cualquier otro Generic Enabler o aplicación FIWARE.
En la capa inferior, para la integración de cualquiera de principales protocolos No-NGSI soportados por FIWARE nativamente, como MQTT, COAP, OneM2M, OPC-UA o LoRaWAN, FogFlow puede reutilizar los conocidos como IoT Agents basándose en un modelo de programación de función de niebla. Con estos adaptadores, FogFlow puede dinámicamente desplegar los adaptadores necesarios para la integración directa de los dispositivos en cualquier nodo edge que lo requiera. De este modo, cualquier nodo FogFlow es capaz de comunicarse con una amplia gama de dispositivos IoT que cubre la práctica totalidad de casos posibles.
Conclusiones
La presente comunicación ha pretendido aportar una visión general de FogFlow como framework de desarrollo y ejecución distribuido para organizar servicios IoT mediante la gestión dinámica de los flujos de procesamiento de datos entre la nube y los bordes de una manera transparente y escalable, presentando sus objetivos de diseño, características tecnológicas clave y propuesta de valor.
También se explica brevemente sus modelos de programación, incluida la topología de servicio para el procesamiento de datos bajo demanda y la función de niebla (fog) para la computación edge sin servidor (serverless).
Se presentan dos posibles casos de uso para mostrar cómo estos dos modelos de programación pueden usarse para realizar servicios de IoT a escala de ciudad. Los dos casos de uso propuestos ayudan a ilustrar cómo los dos modelos de programación (topología de servicio y topología de niebla) pueden usarse para implementar servicios IoT reales, contribuir a la optimización de anchos de bandas y a simplificar toda la problemática y complejidad asociada a la gestión y diseño de este tipo de servicios.
Referencias
- Cheng Bin et. al, 2017, IEEE Internet of Things Journal, “FogFlow: Easy Programming of IoT Services Over Cloud and Edges for Smart Cities”
- Cheng Bin et. al, 2018, NEC Technical Journal, “FogFlow: Orchestrating IoT Services over Cloud and Edges”
- Fiware Catalogue (2 abril 2019)
- FogFlow (2 abril 2019)
- FogFlow: Orchestrating IoT Services over Cloud and Edges (2 abril 2019)