Investigadores de la Escuela Técnica Superior de Ingenieros Informáticos de la Universidad Politécnica de Madrid (UPM) han desarrollado un sistema que aprende del contexto y detecta, genera, almacena y reutiliza los patrones recogidos en los datos ya analizados previamente en tiempo real y que no han podido ser almacenados, precisamente por su ingente cantidad. Mediante este sistema, se puede predecir el momento en el que estos patrones volverán a aparecer e identificar cambios en el contexto que ayuden a detectar fraudes o spam.
Nuestro trabajo se centra en un ámbito que es punta de lanza en materia de minería de datos, en data streams
, explica Ernestina Menasalvas, del Departamento de Lenguajes y Sistemas Informáticos e Ingeniería del Software de la UPM. El sistema permite optimizar el desarrollo de modelos de clasificación de minería de datos reutilizando modelos similares en contextos parecidos. Todo ello mejora las capacidades de aplicar la inteligencia artificial a entornos como ciudades inteligentes, Internet de las cosas, o dispositivos móviles
.
El mecanismo tiene aplicaciones en materia de ciberseguridad, donde la herramienta permitirá detectar patrones similares y prever ataques cibernéticos, mejorando los sistemas de detección y respuesta. También podría aplicarse a la detección de intrusiones y fraudes por vías informáticas y al desarrollo de filtros antispam.
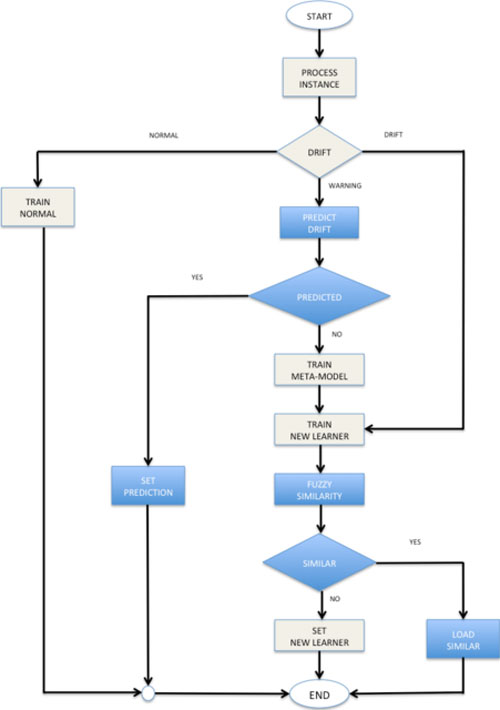
Los cambios de contexto pueden estar originados por hechos conocidos, como aquellos asociados a la climatología o a la estación del año, o provenir de aspectos desconocidos a priori. Para predecirlos, los investigadores de la UPM desarrollaron una función de similitud basada en técnicas de lógica difusa que extiende el comportamiento básico de decisión sí/no. “Una vez que la función determina si existen modelos de clasificación equivalentes para tratar el nuevo contexto, el sistema puede aplicar los mismos de forma directa gracias a su almacenamiento previo en un repositorio”, explica Miguel Ángel Abad, autor de la tesis en la que se exponen los resultados de este trabajo.
El ahorro de recursos es otra de las ventajas que supone este sistema. “Adelantarnos al modo en que se van a comportar los datos supone un ahorro en los recursos computacionales de los dispositivos, por lo que este mecanismo es de aplicación a entornos ubicuos, caracterizados por la existencia de distintos dispositivos que operan en tiempo real y con recursos limitados”, explica Miguel Ángel Abad.
Los resultados de este trabajo se han publicado en la revista especializada Expert Systems With Applications Journal, una publicación de referencia sobre sistemas inteligentes y su aplicación en diferentes campos.