
Investigadores del Instituto Tecnológico de Massachusetts (MIT) han desarrollado una serie de algoritmos para organizar sistemas de control robótico en circunstancias de incertidumbre realilzando pruebas de simulación sobre la idea de drones repartidores de paquetería expuesta por Google y Amazon.


Los llamados ‘Procesos de Decisión de Markov Parcialmente Observables Descentralizados’ (abreviado como Dec-POMDPs), se presentan como una manera de modelar el comportamiento de robots autónomos en circunstancias en las que ni las comunicaciones entre sí, ni sus valoraciones sobre el mundo exterior son perfectas.
Los ‘Dec-POMDPs’ generan modelos matemáticos más rigurosos que un sistema ‘multiagente’ o ‘multielemento’ (no sólo robots, sino cualquier dispositivo conectado) bajo condiciones de incertidumbre. No obstante, incluso para los casos más simples, lleva mucho tiempo el resolverlos.
El pasado verano, investigadores del MIT presentaron un estudio en el que hacían los Dec-POMDPs más prácticos para los sistemas robóticos existentes. El informe mostraba que los Dec-POMDPs pueden determinar la manera óptima de organizar los sistemas de control robótico de bajo nivel para realizar tareas colectivas, con un enfoque que los hace computacionalmente manejables.


Durante la Conferencia Internacional sobre Robótica y Automatización celebrada el pasado año, otro equipo de investigadores del MIT fue un paso más allá con este enfoque: el nuevo estudio puede generar sistemas de control de bajo nivel desde el principio y continua resolviendo los modelos Dec-POMDP en un plazo de tiempo razonable.
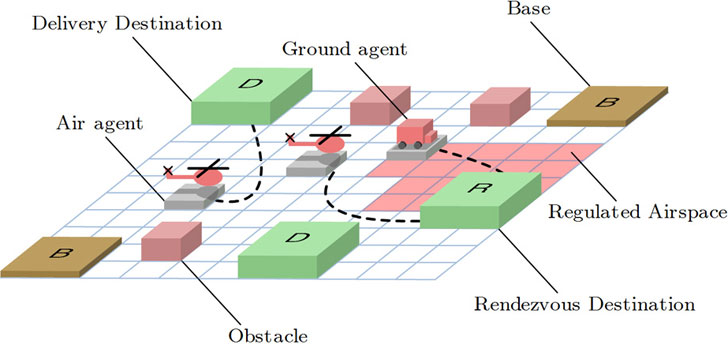
Los investigadores han probado su sistema en un pequeño grupo de helicópteros no tripulados, en un escenario que simula la idea del sistema de reparto de paquetería con drones concebido por Amazon y Google, con la limitación añadida de que estos vehículos no tripulados no pueden comunicarse entre ellos.


Según explica Shayegan Omidshafiei, estudiante de graduado en aeronáutica y astronáutica y principal autor del nuevo documento, hay una fase de la planicación offline, donde los elementos pueden descifrar una polítcia conjunta, es decir, ‘si yo realizo una serie de acciones, dado que he hecho estas observaciones durante la ejecución conectada, y tú realizas otra serie de acciones, dado que has hecho estas observaciones, podemos afirmar que el conjunto de acciones que realizamos está muy cerca de ser el óptimo’
. Y continúa: en ningún momento, durante la fase online, los elementos paran y dicen ‘Esto es lo que creo. Esto es lo que crees. Vamos a consensuar cuál es la mejor opción en términos generales y replanificar’. Cada uno realiza únicamente sus propias tareas
.
Lo que hace a los Dec-POMDPs tan complicados es que éstos tienen que tener en cuenta, explícitamente, la incertidumbre. Un robot autónomo puede depender de sus sensores para determinar su localización, pero sus sensores probablemente tendrán un margen de error, por lo que cualquier lectura dada debe ser interpretada como una distribución de probabilidad definida alrededor de la medición real.

Incluso con las medidas exactas, a pesar de que puedan ser abiertas a interpretación, el robot necesitará construir una distribución de probabilidad de posibles situaciones por encima de la distribución de probabilidad de las lecturas de sensores. Así, hay que elegir una serie de acciones, pero sus posibles acciones podrán tener sus propias probabilidades de éxito. Y si el robot está participando en una tarea colaborativa, también debe tener en cuenta las ubicaciones probables de otros robots y sus consiguientes probabilidades de tomar acciones particulares.
Para facilitar la resolución, un Dec-POMDP descompone en dos problemas con sus correspondientes gráficos. Cada gráfico es una representación consistente en nodos, normalmente representados por círculos del estilo de redes de diagramas y árboles de familia.

Los primeros algoritmos constituyen un gráfico en el que cada nodo representa una posibilidad, lo que significa una probabilidad estimada del estado del elemento y estado global. El algoritmo crea una serie de procedimientos de control que pueden desplazar al elemento por las diferentes posibilidades.
A estos procedimientos se les llama ‘macro-acciones’, una única ‘macro-acción’ puede alojar a variedad de posibilidades tanto en origen como en destino, los algoritmos planificados eliminan algunas complejidades del problema antes de pasar a la siguiente fase.
Para cada elemento, el algoritmo construye un segundo gráfico en el que los nodos representan macro-acciones definidas en los pasos previos, y los bordes representan la transición entre macro-acciones a la luz de la observación.

En el experimento reportado, los investigadores realizan una serie de simulaciones de las tareas que los elementos deberán llevar a cabo, asumiendo diferentes posibilidades al azar al inicio de cada simulación. Según el nivel de éxito en la realización de las tareas en cada ocasión, el algoritmo de planificación asigna diferentes pesos a las ‘macro-acciones’ en los nodos del gráfico y en la transición entre ellos.
El resultado es una captura gráfica que muestra la probabilidad de que un elemento deba llevar a cabo una macro-acción particular teniendo en cuenta las acciones pasadas y las observaciones del contexto alrededor. Aunque estas probabilidades estaban basadas en simulaciones, en principio, dispositivos autónomos podrían realizar el mismo tipo de gráfico a través de la exploración física de sus entornos.
Finalmente, el algoritmo selecciona las macro-acciones y transiciones con los mayores pesos. Esto produce un plan determinista que cada elemento puede seguir: ‘Después de realizar la macro-acción A, si hace la medición B, ejecutar la macro-acción C’.